
近年來,隨著網絡購物的興起,對于物流運輸行業的要求也越來越高,而大件商品的物流仍是一個難題,如運輸路徑、包裝費用等.現有的研究普遍忽略了大范圍物流運輸路徑規劃的時間復雜度.針對大件商品物流的路徑規劃問題[1][2][3][4][5],本文將改進的K-means聚類算法與傳統的Floyd算法相結合,降低了路徑規劃問題所需的時間復雜度.
地圖上所有非物流中心的樣本點,稱為普通物流地點.由物流中心所管轄的普通物流地點的集合稱為物流子區域.假設存在一個屬于物流子區域A(以點A為聚類中心的物流子區域)的點a,若a與屬于其他物流子區域的點直接相連,則稱該點a為區域間相連點,被點a相連的兩個物流子區域稱為相鄰物流子區域.
Step1求普通物流地點a到各個物流中心的歐式距離.記普通物流地點a對應的坐標為(x0,y0),其他物流中心的坐標為(xi,yi)(i=1,2,3,…),點a到其他各個物流中心的歐式距離為

Step2對所有的普通物流地點a到其他各個物流中心的歐式距離Di(i=1,2,3,…)進行比較,找出其中與點a歐式距離最小的物流中心,兩點間的歐氏距離記為Dmin,即

Step3將所有普通物流地點依據其所最近的物流中心進行分區.
Step4對所有物流中心所劃分的物流區域內的所有普通物流地點進行內部檢查.提取出其中的異常點,重新進行聚類(此后的聚類排除以當前物流中心為聚類中心的情況).
Step5將聚類結果存儲,以便之后使用Floyd算法時調用.
對于點X,若當點X被聚類到以點A為聚類中心的區域中時,X與區域A內的其他點未直接相連,則稱X為異常點.圖1中的點4即為異常點.

若存在一個屬于物流子區域A的點a,點a與屬于物流子區域B的點b直接相連,則稱點a與點b為區域間相連點,兩個物流子區域A和B稱為相鄰物流子區域.圖1中的點2和點6即為兩個物流子區域A和B間的相連點,A和B為相鄰物流子區域.
以圖1為例說明如何排除異常點.利用鄰接矩陣的深度優先遍歷算法[8],遍歷各個物流中心的物流子區域是否存在路徑(路徑上的點均在物流子區域內).對于物流子區域A,其鄰接矩陣為

在傳統的Floyd算法中,假設從點a到達點b間最短路徑距離為Xmin,且點a與點b間存在i個節點X1,X2,…,Xi.分別記點a到節點X1的距離為x1,節點X1到節點X2的距離為x2,以此類推,節點Xi到點b的距離為xi+1.那么應該滿足

如果存在另一路徑,點a與點b間存在j個節點Y1,Y2,…,Yj,分別記點a到節點Y1的距離為y1,節點Y1到節點Y2的距離為y2,以此類推,節點Yj到點b的距離為yj+1,使得

那么,令

Floyd算法代碼為:

可以發現,傳統的Floyd算法的時間復雜度為O (n3).
Step1通過改進的K-means聚類算法將各普通物流地點聚類到對應的物流中心,并存儲以便反復調用;
Step2遍歷所有物流點,得到各個相鄰物流子區域的區域間相連點,用傳統Floyd算法[9]求出物流中心到物流子區域內各相連點間的最短路徑和距離;
Step3利用Step2得到的物流中心、區域間相連點和兩者間最短距離以及區域間相連點的距離構造鄰接矩陣,將所有物流點構成的物流區域降維,使用傳統Floyd算法得到物流中心間的最短路徑.將得到的數據進行存儲,以便反復調用.
在物流子區域內進行路徑規劃時,僅需對該物流子區域內的普通物流地點使用傳統Floyd算法進行路徑規劃即可.
當物流運輸的終點不在出發點所在物流區域時,需要提前計算各個物流中心間的最短路徑,并將得到的數據進行存儲,以用于跨區域路徑規劃.具體過程為:
Step1確定物流運輸的起點a和終點b所在物流子區域所對應的物流中心;
Step2調用前期準備Step3得到的數據,確定起點a與終點b所屬物流中心A,B間的最短路徑;
Step3構造物流子區域內的鄰接矩陣,用Floyd算法規劃起點a到物流中心A的最短路徑;
Step4利用各物流中心間最短距離構造新的鄰接矩陣(此時鄰接矩陣考慮的節點僅為物流中心),再根據該鄰接矩陣與Floyd算法規劃物流中心A到B的最短路徑,得到物流中心間的最短路徑,實現物流子區域間的轉移;
Step5記錄最后一個區域間相連點,即物流中心間最短路徑上第一個屬于終點所在物流子區域B的節點q;
Step6根據物流子區域B的節點構造鄰接矩陣,再次進行Floyd算法,規劃點q到點b的最短路徑.
假設存在物流運輸地圖(見圖2),按照改進的K-means聚類算法進行物流子區域的劃分,結果見圖3.經過物流中心間的路徑規劃,可將全地圖簡化.以物流中心A,B為例,簡化結果見圖4.



在物流子區域A內,規劃起點為點a,終點為點2的最優路徑.傳統Floyd算法求解最短路程為40,路徑為a→A→1→2.使用結合改進K-means聚類算法的Floyd算法求得的最短路程同樣為40,路徑為a→A→1→2.
算法復雜度分析:此情況下傳統的Floyd算法考慮了所有物流子區域中的所有節點,其算法復雜度[10]為O (n3),n為所有節點的總數.而改進的Floyd算法則只需考慮物流子區域所有節點數量,其算法復雜度僅為O((k n)3),kn為該物流子區域內的節點數量(0
假設起點b在物流子區域B內,終點6在物流子區域C內.傳統Floyd算法求解最短路程為125,路徑為b→B→3→4→C→5→6.使用結合改進K-means聚類算法的Floyd算法求得的最短路程同樣為125,路徑為b→B→3→4→C→5→6.
算法復雜度分析:此情況下傳統的Floyd算法考慮了所有物流子區域中的所有節點,其算法復雜度為O (n3),n為所有節點的總數.而改進的Floyd算法則的算法復雜度分為三個部分.第一部分,起點b到物流中心B路徑規劃,其復雜度為O((k1n)3),k1n為物流子區域B內的節點數量;第二部分,物流中心B到C的路徑規劃,其復雜度為O((k2n)3),k2n為物流中心的總數;第三部分,最后一個區域間相連點q到終點6的路徑規劃,其復雜度為O((k3n)3),k3n為物流子區域C內的節點數量,這里0
傳統的Floyd算法需要考慮全地圖中的每個普通物流地點與物流中心.假設物流點的總數為n,則此時傳統Floyd算法的時間復雜度為O (n3),故隨著地圖規模的增大,其計算所需時間將快速增長.
結合K-means聚類算法的Floyd算法其時間復雜度為O((k n)3)(0
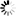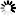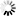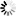


 滬公網安備 31011202008041號
滬公網安備 31011202008041號













